Як працювати з алгоритмами ШІ на Python: розповідаємо покроково

Застосування Python в алгоритмах ШІ відкриває величезні можливості для досвідчених програмістів та перспективних фахівців на початку свого професійного шляху. Технологія штучного інтелекту швидко зростає та охоплює різні рішення у маркетингу, електронній комерції, охороні здоров’я, транспорті та інших секторах бізнесу й промисловості. Тому величезна кількість інструментів та бібліотек, що спеціально надаються для розробки на Python та ШІ, необхідні й важливі у сучасному ІТ-середовищі.
У цьому пості ми концентруємося на перевагах застосування Python для штучного інтелекту, а також бібліотеках та стратегіях послідовної реалізації алгоритмів ШІ.

Попри те, що Python вже має вбудовані функції для успішної роботи з ШІ, деякі бібліотеки штучного інтелекту, проте, будуть корисні для розширення можливостей вашого майбутнього рішення:
Насамперед вам необхідно якомога точніше визначити проблему. Це передбачає розуміння природи даних, з якими ви працюєте, та можливих обмежень, що виникають на шляху до мети. Коли у вас з’явиться уявлення про все перераховане вище, можна переходити до другого кроку – вибору відповідного алгоритму.
Різні види алгоритмів ШІ (некероване навчання – unsupervised learning, кероване навчання – supervised learning, навчання з підкріпленням – reinforcement learning) передбачають різні можливості. Наприклад, алгоритми навчання з учителем, а саме дерева рішень та лінійна регресія, ідеально підходять для роботи з розміченими даними. І навпаки, якщо ваші дані нерозмічені й вам потрібно виявити закономірності всередині них, найбільш корисними будуть аналіз головних компонентів або кластеризація методом k-середніх (k-means clustering method) у рамках навчання без вчителя.
Цей етап починається з вибору інтегрованого середовища розробки чи IDE. Іншими словами, це набір інструментів для тестування, написання та налагодження коду. Visual Studio Code, PyCharm та Jupyter Notebook – одні з найпопулярніших варіантів. Для налаштування віртуального середовища вам знадобляться додаткові інструменти (Conda або Virtualenv) або вбудований модуль Venv.

На цьому етапі вам необхідно обрати бібліотеку відповідно до проєктних вимог, аби використати всі переваги Python. Обирайте бібліотеки, що мають високу продуктивність, наприклад Pandas, NumPy і Matplotlib. Після визначення вимог до даних розпочніть пошук відповідних наборів даних із загальнодоступних репозиторіїв або за допомогою методів очищення вебсторінок. А далі ретельно вивчіть дані, щоб виявити та виправити будь-які невідповідності, дублювання чи пропущені значення.
Основа – це розуміння того, чого вам потрібно досягти: різні алгоритми ШІ допомагають класифікувати, кластеризувати чи регресувати дані. Ваша ціль також визначає показники продуктивності. Наприклад, якщо ви прагнете класифікації даних, точність буде вашим головним критерієм. Найбільш популярні алгоритми ШІ передбачають кластеризацію методом k-середніх для об’єднання схожих об’єктів у групи, лінійну регресію для отримання безперервного прогнозування змінних та дерева рішень для процесів обробки даних, пов’язаних із класифікацією.
Перший інструмент, який ви можете використовувати, це train-test split: навчальний набір допомагає моделі вивчити дані, а тестувальний набір оцінює продуктивність. Щоб проаналізувати продуктивність вашої моделі, ви просто порівнюєте фактичні значення з прогнозованими значеннями тестового набору. Крім того, застосування методів перехресної перевірки сприяє точній оцінці продуктивності: ви можете розділити набори даних на k-групи (складки) зразків та провести навчання та тестування. Щоразу тестуються різні складки, а інші тим часом навчаються. Ви також можете звернутися до матриці невідповідності (confusion matrix), якщо ваша мета передбачає оцінку моделей класифікації даних. Матриця невідповідності візуалізує точність прогнозування кожного класу в наборі даних.
Для більш детального та поглибленого огляду синтаксису та бібліотек Python ми наведемо кілька прикладів. Нижче – простий приклад моделі навчання з використанням TensorFlow в Python. У цьому прикладі використовується Sequential API, який є простим способом побудови моделей шар за шаром.
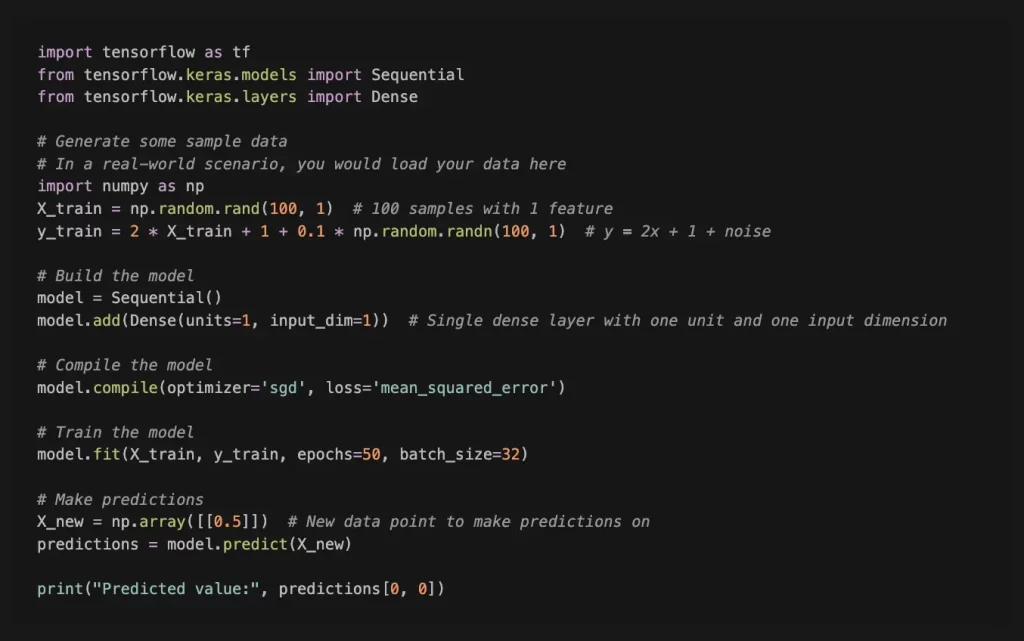
У цьому прикладі ми створюємо просту модель лінійної регресії для прогнозування результату (y) на основі вхідних даних (X). Модель навчається з використанням стохастичного градієнтного спуску («sgd») як оптимізатор та середньоквадратична помилка («mean_squared_error») як функція втрат. Навчальні дані складаються з 100 вибірок з однією ознакою, а цільові значення (y) генеруються з використанням лінійної залежності і деякого випадкового шуму.
Це дуже простий приклад, і в реальних сценаріях вам може знадобитися обробляти складніші дані, використовувати різні типи шарів і точно налаштовувати параметри для підвищення продуктивності. Крім того, важливо відповідним чином попередньо обробити та нормалізувати дані.
Обробка природної мови (NLP) – область ШІ, відома навіть звичайним користувачам, оскільки це рішення поширене в різних програмах та інструментах ШІ. Natural Language Toolkit (NLTK) – популярна бібліотека Python для NLP. Нижче наведено простий приклад використання NLTK для обробки та аналізу настроїв тексту.
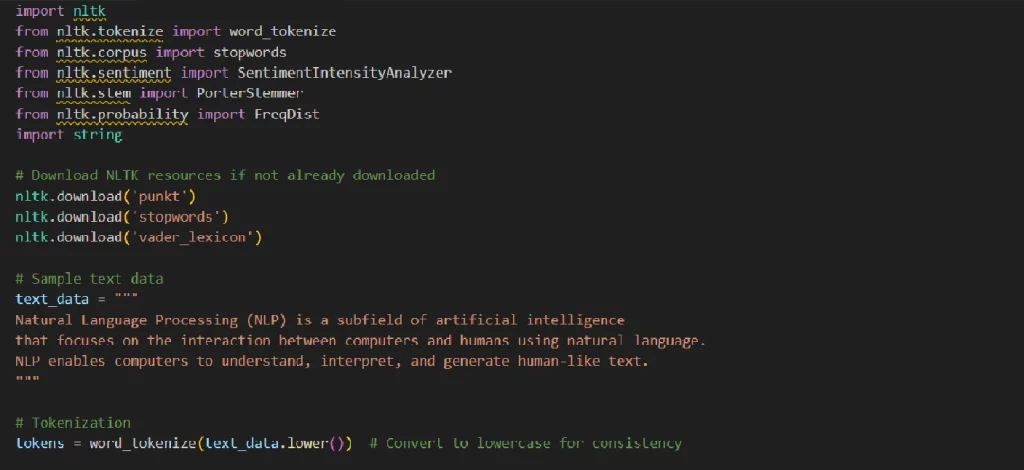
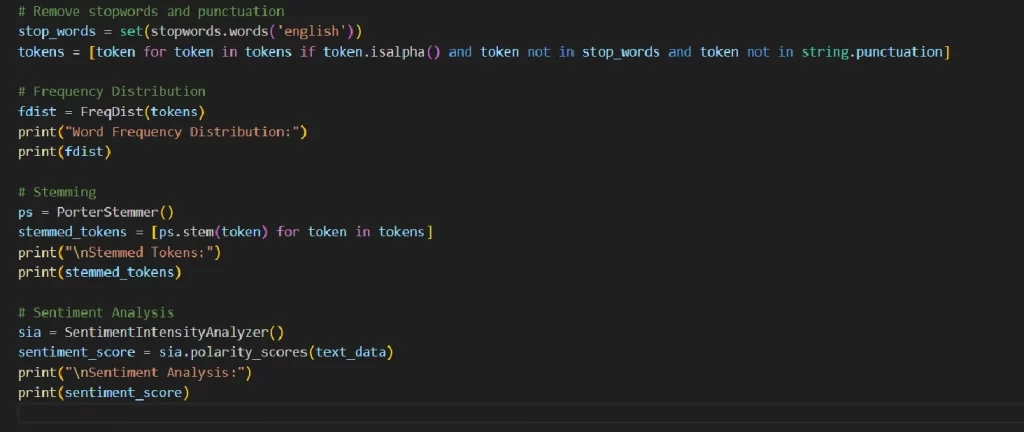
У цьому прикладі можна побачити основні елементи NLP: Токенізація тексту в слова; Видалення стоп-слів та розділових знаків; Частотний розподіл слів; Коригування слів; Аналіз настрою тексту.
Завдяки універсальності, масштабованості та надійній екосистемі бібліотек Python ефективно працює з ШІ. Реалізація алгоритмів штучного інтелекту в Python чітко визначена та послідовна, якщо правильно визначити основне завдання та відповідні показники продуктивності.
PNN Soft радо допоможе вам розширити програмні можливості поточного рішення або розробити систему на основі штучного інтелекту з нуля. Ми маємо 20-річний досвід роботи у співпраці зі 150 країнами, але ніколи не припиняємо вдосконалювати навички та аналізувати інновативні тенденції розробки програмного забезпечення.




