Пошаговое руководство по работе с алгоритмами ИИ на Python

Применение Python в алгоритмах ИИ открывает огромные возможности для опытных программистов и перспективных специалистов в начале своего профессионального пути. Область искусственного интеллекта быстро растет и охватывает различные решения в маркетинге, электронной коммерции, здравоохранении, транспорте и других секторах бизнеса. Поэтому огромное количество инструментов и библиотек, специально предоставляемых Python для реализации ИИ, необходимы и важны в современной ИТ-среде.
В этом посте мы концентрируемся на преимуществах применения Python для искусственного интеллекта, библиотеках и стратегий последовательной реализации алгоритмов ИИ.

Несмотря на то, что Python уже обладает встроенными функциями для успешной работы с ИИ, некоторые библиотеки искусственного интеллекта, тем не менее, будут полезны для расширения возможностей вашего будущего решения:
Перво-наперво вам необходимо как можно точнее определить проблему. Это подразумевает понимание данных, с которыми вы работаете, и возможных ограничений, возникающих на пути к вашей цели. Когда у вас появится представление обо всем вышеперечисленном, можно переходить ко второму шагу – выбору соответствующего алгоритма.
Различные виды алгоритмов ИИ (обучение без учителя – unsupervised learning, обучение с учителем – supervised learning, обучение с подкреплением – reinforcement learning) предполагают различные возможности. Например, алгоритмы обучения с учителем, а именно деревья решений и линейная регрессия, идеально подходят для работы с размеченными данными. И наоборот, если ваши данные не размечены и вам нужно выявить закономерности внутри них, наиболее полезными будут анализ главных компонентов или кластеризация k-средних (k-means clustering method) в рамках обучения без учителя.
Этот этап начинается с выбора интегрированной среды разработки или IDE. Другими словами, это набор инструментов для тестирования, написания и отладки кода. Visual Studio Code, PyCharm и Jupyter Notebook – одни из самых популярных вариантов. Для настройки виртуальной среды вам потребуются либо сторонние инструменты (Conda или Virtualenv), либо встроенный модуль Venv.
На этом этапе вам необходимо выбрать библиотеку в соответствии с требованиями проекта. Выбирайте те, у которых высокая производительность, например Pandas, NumPy и Matplotlib. После определения требований к данным приступайте к получению соответствующих наборов данных из общедоступных репозиториев или с помощью методов очистки веб-страниц. Наконец, тщательно изучите данные, чтобы выявить и устранить любые несоответствия, дублирования или пропущенные значения.
Основа – это понимание того, что вам нужно достичь: различные алгоритмы ИИ помогают классифицировать, кластеризовать или регрессировать данные. Ваша цель также определяет показатели производительности. Например, если вы стремитесь к классификации данных, точность будет вашим главным критерием. Наиболее востребованные алгоритмы ИИ предполагают кластеризацию к-средних для объединения схожих объектов в группы, линейную регрессию для получения непрерывного прогнозирования переменных и деревья решений для процессов обработки данных, связанных с классификацией.

Первый инструмент, который вы можете использовать, — это train-test split: обучающий набор помогает модели изучить данные, а тестирующий набор оценивает производительность. Чтобы проанализировать производительность вашей модели, вы просто сравниваете фактические значения с прогнозируемыми значениями из тестового набора. Кроме того, использование методов перекрестной проверки способствует точной оценке производительности: вы можете разделить наборы данных на k-группы (складки) образцов и провести обучение и тестирование. Каждый раз тестируются разные складки, а остальные, незадействованные в тестировании данные, обучаются. В качестве альтернативы вы можете обратиться к матрице путаницы, если ваша цель подразумевает оценку моделей классификации данных. Матрица путаницы визуализирует точность прогнозирования для каждого класса в наборе данных.
Для более детального и углубленного обзора синтаксиса и библиотек Python мы приведем несколько примеров. Ниже — простой пример модели обучения с использованием TensorFlow в Python. В этом примере используется Sequential API, который служит простым способом построения моделей слой за слоем.
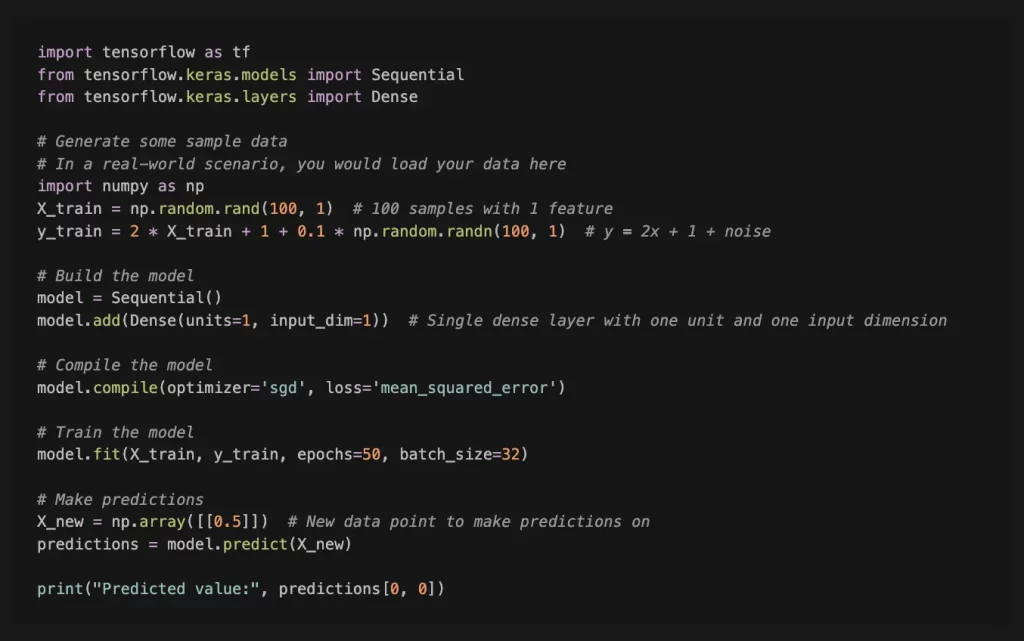
В этом примере мы создаем простую модель линейной регрессии для прогнозирования результата («y») на основе входных данных («X»). Модель обучается с использованием стохастического градиентного спуска («sgd») в качестве оптимизатора и среднеквадратической ошибки («mean_squared_error») в качестве функции потерь. Обучающие данные состоят из 100 выборок с одним признаком, а целевые значения («y») генерируются с использованием линейной зависимости и некоторого случайного шума.
Это очень простой пример, и в реальных сценариях вам может потребоваться обрабатывать более сложные данные, использовать разные типы слоев и точно настраивать параметры для повышения производительности. Кроме того, важно соответствующим образом предварительно обработать и нормализовать данные.
Обработка естественного языка (NLP) — область ИИ, которая на слуху даже у обычных пользователей, поскольку решение широко распространено в различных программах и инструментах ИИ. Natural Language Toolkit (NLTK) — популярная библиотека Python для NLP. Ниже приведен простой пример использования NLTK для обработки и анализа настроений текста.
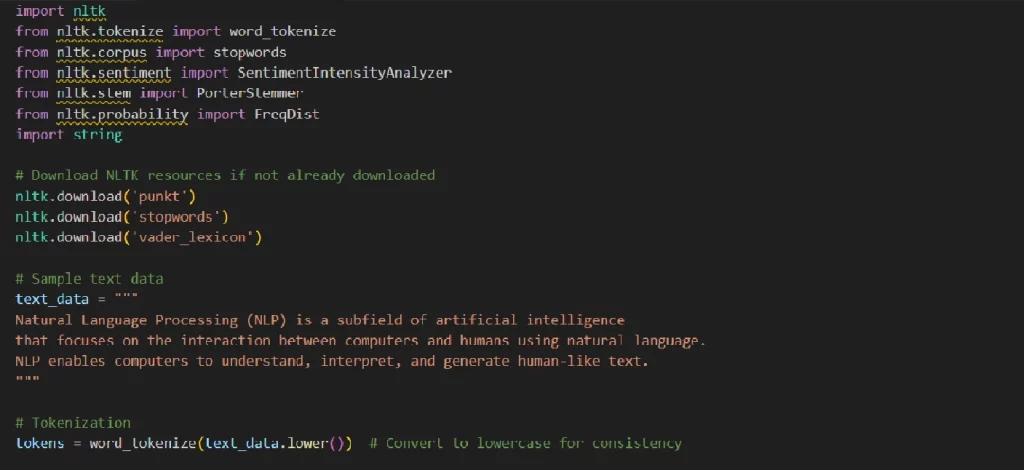
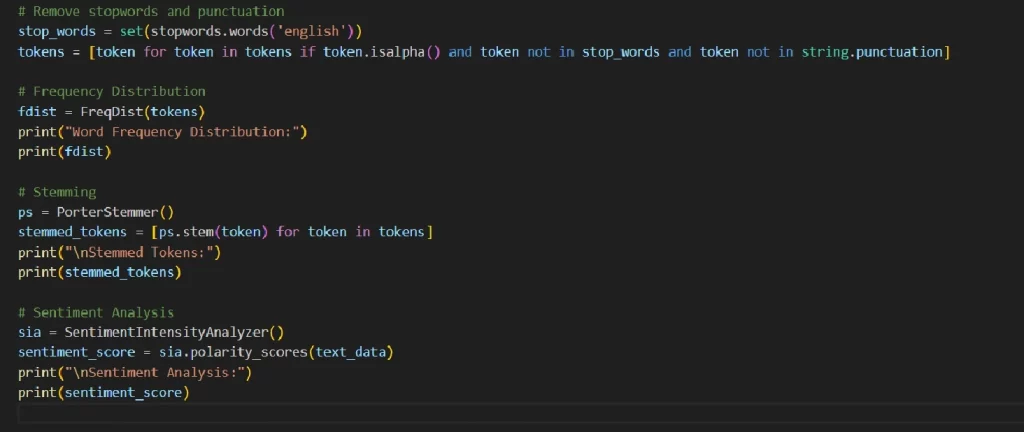
В этом примере вы можете увидеть основные элементы NLP: Токенизация текста в слова; Удаление стоп-слов и знаков препинания; Частотное распределение слов; Корректировка слов; Анализ настроения текста.
Благодаря универсальности, масштабируемости и надежной экосистеме библиотек Python проявляет себя как многообещающим инструмент, эффективно работающий с ИИ. Реализация алгоритмов искусственного интеллекта в Python четко определена и последовательна, если правильно определить задачу и соответствующие показатели производительности.
PNN Soft с радостью поможет вам расширить программные возможности существующего решения или разработать систему на основе искусственного интеллекта с нуля. У нас 20-летний опыт работы в сотрудничестве со 150 странами, но мы никогда не прекращаем оттачивать навыки и анализировать передовые тенденции разработки программного обеспечения.