HBase и Cassandra: какую базу данных выбрать?

Выбор наиболее эффективной системы управления базами данных имеет важное значение для оптимизации операций и последовательного процесса разработки. В эпоху значительного развития науки о данных и аналитики больших данных программисты особенно ценят масштабируемость и скорость баз данных NoSQL.
В PNN Tech мы часто отвечаем на вопрос, какая база данных работает более плавно и эффективно в рамках конкретного проекта по работе с большими данными — другими словами, это тема HBase или Cassandra. Однако для правильного ответа следует учитывать множество деталей, связанных с производительностью и архитектурой. Начнем наш сравнительный обзор с рассмотрения основ обеих систем.
Обе базы данных NoSQL имеют открытый исходный код и широко используются в качестве хранилищ данных. Архитектура Apache Cassandra была смоделирована по образцу Bigtable и DynamoDB от Amazon, а архитектура HBase была создана для работы на HDRS в системах Hadoop. Первая база данных служит примером хранилища данных «ключ-значение», содержащего упорядоченные записи столбцов. Apache также состоит из столбцов с часто используемыми атрибутами, к которым можно быстро получить доступ; система упорядочена и индексирована, что упрощает чтение данных.
Среди известных компаний, использующих Apache Cassandra, — Apple, CVS Health и Verizon Wireless. В число лидеров рынка, внедривших Apache HBase, входят Bank of America, JP Morgan Chase и American Express.
HBase имеет таблицу, ориентированную на столбцы, на верхнем уровне. Каждая таблица имеет наборы ключей строк, которые являются первичными ключами в традиционной реляционной базе данных. HBase делит строки на семейства столбцов — связанные столбцы данных.
Что касается модели данных Cassandra, ее можно описать как секционированное хранилище строк. На верхнем уровне находится пространство ключей с таблицами (семействами столбцов). В семействе столбцов строки хранятся на одном диске.
HBase поддерживает авторизацию и аутентификацию: при необходимости первую можно ограничить уровнем ячейки. Аутентификация Kerberos в кластере обеспечивает надежное шифрование клиента.
Аналогично, Cassandra поддерживает аутентификацию и авторизацию. Доступ к некоторым записям может быть ограничен в зависимости от должности сотрудника. В Cassandra 4+ администрация компании может видеть последовательность действий, выполняемых с конкретными данными, посредством ведения журнала аудита.
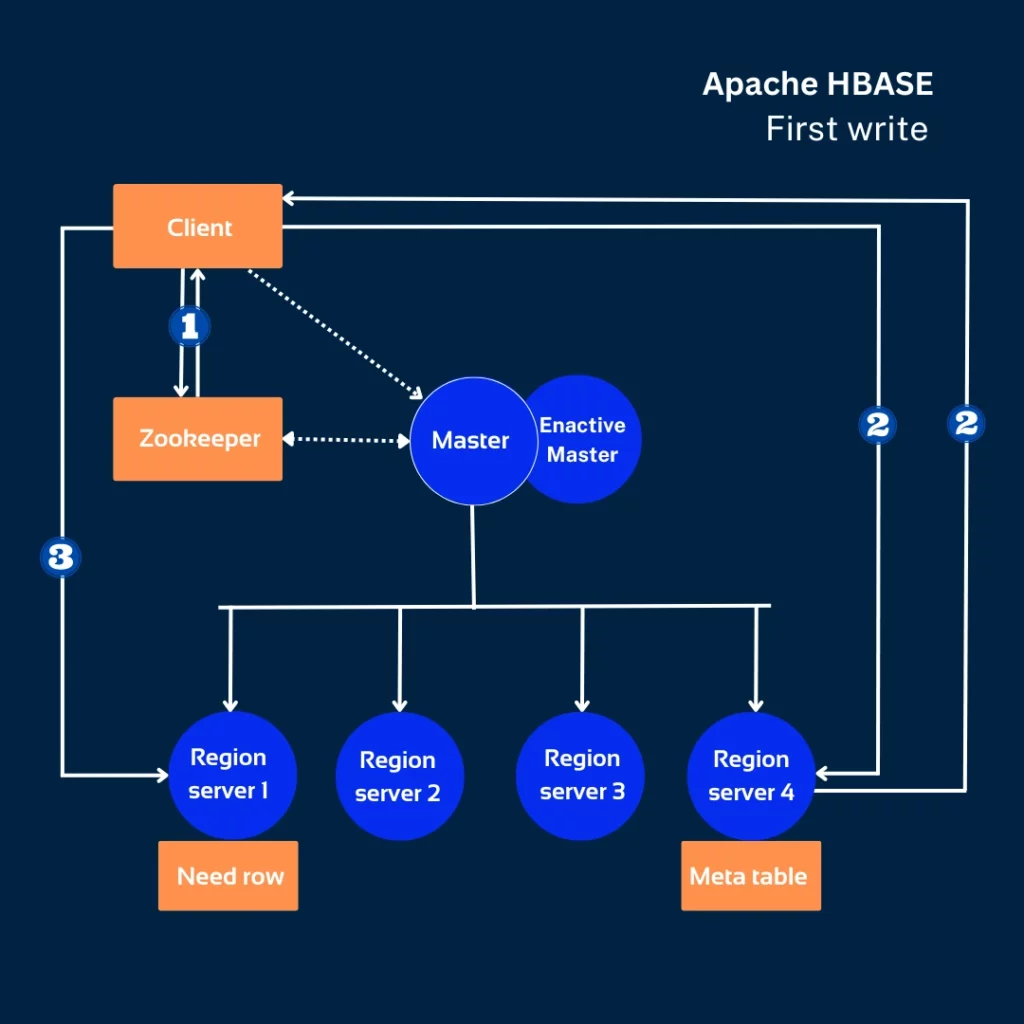
Поскольку Cassandra специально создана для массового и крупномасштабного приема данных, она позволяет быстрее записывать данные, одновременно кэшировать и регистрировать их. HBase необходимо взаимодействовать с ZooKeeper и HMaster, чтобы определить, где следует разместить информацию, что замедляет производительность этой базы данных.
Кроме того, Cassandra имеет тенденцию считывать данные медленнее, поскольку их приходится извлекать через узлы, содержащие информацию. Благодаря поддержке HDFS с кэшами и фильтрами Блума Hbase считывает данные более оперативно.
Функция транзакций ACID в HBase все еще находится в стадии бета-тестирования. Для сравнения, Cassandra пока не поддерживает транзакции и не имеет возможности отката. Однако вы по-прежнему можете использовать облегченные транзакции, что подразумевает обновление записей.
Что касается языка запросов, в Cassandra есть CQL — SQL-подобный язык, позволяющий выбирать, вставлять, удалять и обновлять записи. Однако следует иметь в виду, что недостаточно оптимизированные запросы могут отрицательно сказаться на производительности кластера. CQL можно использовать либо с кластером Cassandra, либо с клиентскими библиотеками Apache Cassandra.
Оболочку HBase можно считать ближайшей альтернативой языку запросов; пользователи могут взаимодействовать с данными с помощью команд put, create, scan и других команд. В случае добавления языка Apache Phoenix вы создадите впечатление SQL-подобного языка запросов. Эксперты PNN Soft используют Java API в кластере HBase для получения расширенных возможностей по вставке, созданию и обновлению важных наборов данных.
HBase содержит HDFS для репликации данных, которая, учитывая стойку, отдает приоритет различным сетевым серверам. В результате система предотвращает потерю данных и переносит единичные сбои в сети.
В Cassandra настройки репликации размещаются в отдельных пространствах ключей, а некоторые из них также могут учитывать стойку. Однако, наоборот, Cassandra не имеет главного узла или первичной реплики для конкретной записи. Система примечательна своим центром обработки данных – определением стоек/наборов узлов в конкретном географическом регионе. Модель данных включает в себя один или несколько центров обработки данных с возможностью репликации между ними.
Другими словами, у вас есть одна база данных с различными местоположениями, что приводит к снижению задержек и повышению согласованности данных в разных регионах.
Разработчики PNN Soft могут масштабировать HBase, добавляя дополнительные узлы в кластер, а зачастую и региональные серверы. Система разделит наборы данных на новые регионы, если объем слишком велик. Следовательно, добавление региональных серверов является ключом к более эффективному распределению нагрузки.
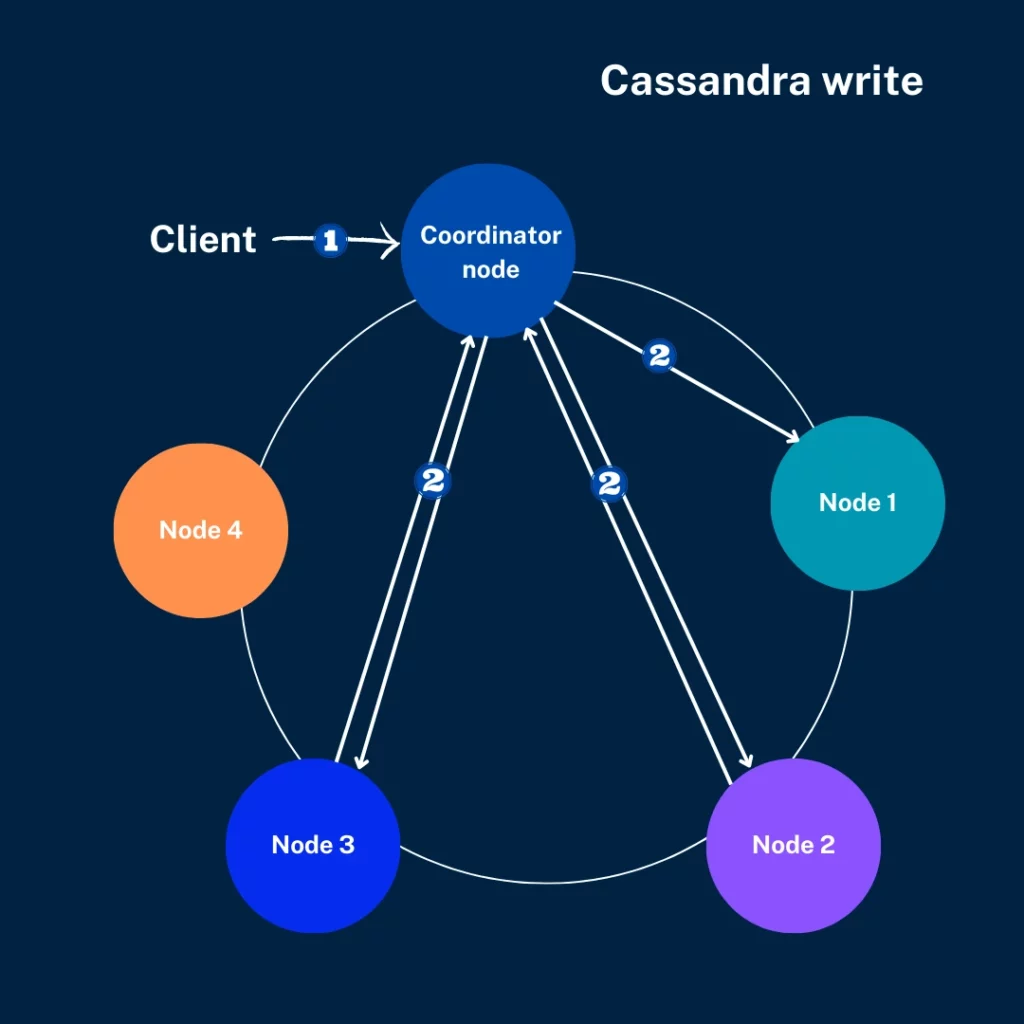
Поскольку Cassandra содержит согласованный хеш для раздела данных в кластере для узлов внутри, вновь созданные узлы приводят к немедленному распространению данных. Несколько факторов имеют решающее значение для объема данных: настройки репликации, общий объем данных, количество узлов и т. д.
Cassandra также можно масштабировать, добавляя в кластер дополнительные узлы. Cassandra использует согласованный хэш для равномерного распределения данных в кластере по узлам внутри. Добавление новых узлов в кластер немедленно распределяет данные по этому узлу. Объем данных зависит от множества факторов, таких как общий объем данных в кластере, количество узлов, настройки репликации и т. д.
И HBase, и Cassandra были разработаны как распределенные базы данных и могут эффективно масштабироваться до сотен узлов.
Как мы уже упоминали, обе системы предназначены для хранения и обработки больших наборов данных. Мы советуем использовать HBase, чтобы в полной мере воспользоваться преимуществами HDFS и Hadoop. Это особенно полезно для секторов здравоохранения, телекоммуникаций и финансов.
Cassandra, в свою очередь, отлично подходит там, где вашей компании необходимо оперативно хранить большие объемы данных. Например, когда хранение больших наборов данных имеет решающее значение, и вам придется обращаться к ним реже. Одним из примеров такой тенденции является технология Интернета вещей.
HBase будет наиболее логичным выбором, если вам нужно воспользоваться возможностями Hadoop (например, MapReduce). Однако, если вы нацелены на оптимизацию развертывания инфраструктуры, Cassandra будет более выгодна для вашей компании. То же самое применимо, если вам нужно работать с репликацией данных между географическими регионами: в Cassandra встроена нативная поддержка.
По опыту PNN Soft, еще одним преимуществом Cassandra является более высокая поддержка со стороны сообщества консультантов — как при использовании облачных, так и on-prem решений, в случае неисправности кластеров и т. д.
Мы надеемся дать вам некоторую ясность в вопросе, какую базу данных выбрать. Если вам нужна дополнительная консультация о разнице между HBase и Cassandra в соответствии с вашими бизнес-целями, пожалуйста, не стесняйтесь обращаться к команде PNN Soft.





